Matrix Factorization Collaborative Filtering

Photo by: Nathan Dumlao on Unsplash
Recommender systems is a specific type of information filtering technique that attempts to predict information items that are likely of interest to the user. Collaborative Filtering(CF) is the most popular approach in recommender system research.
How Collaborative Filtering works?
Collaborative Filtering builds a model from user’s past behaviour (item based) as well as similar decisions made by other users(user based); then use that model for the prediction. It employs similarity measures either in a neighbourhood search space or in a latent space to extract this information from data.
Thinking CF in terms of Google ranking algorithm?
The most significant difference between them is that the latter finds efficiently web pages in the world wide web whereas the first finds efficiently items like products or movies in a specific application context like Amazon and Netflix.
To put it straightforward, given a user query, the PageRanki algorithm returns an order of web pages such that the one of the top is the one that a user will be more likely interested in. Google search results vary, even on the same device and using the same keyword phrase because of user’s personal search and click history factor.
Different CF working approaches?
Similarly, CF exploits user’s history by using
- heuristic models (based on Pearson/Cosine/Jacquard functions that compute pair-wise similarities)
- item-based neighbourhood: find item i that is similar to k items which users has bought/search for/click to.
- user-based neighbourhood: user A bought items 1,2,3 and user B bought items 1,2,4. User A will likely buy item 4.
- factor models (based on mathematical techniques that infer factors by minimising the reconstruction error based on observed data.)
- matrix factorization: finds hidden similarity layer between the users and the items
- hybrid models

Pearson correlation computes similarity between users v and u
In this post, you’ll read about:
- What is the intuition of Matrix Factorization?
- How it works?
Matrix Factorization is a learning algorithm belonging to latent factor models and has been used in many machine learning applications like training deep networks, modelling a knowledge base and recommender systems. It allows for:
- solving linear equations
- compressing data
- transforming data
|
|
Let’s go a step behind and remember our schooling years in math class.
Factorization means decomposing an entity into multiple entries - that can be typically ‘managed’ more easily. For example, 8 is the product of 4 and 2.
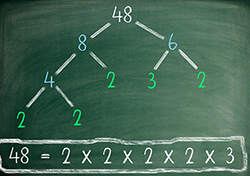
Image Source: Science ABC
Extending this idea to matrix factorization, means decomposing a matrix into two or more matrices. This helps us to extract these latent factors in data structures to find the hidden similarity layer between the users, items and interest (rating).
The intuition behind using matrix factorization is that it assumes that there are some latent features (k) specific to a domain that influence users’ interest. These latent features are much smaller than the number of users and the number of items (k<min(m,n)).
They are learnt by minimising the reconstruction error based on observed data.
Problem Definition
|
|
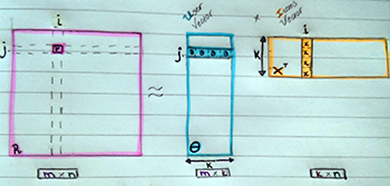
Factorizing the Rating Matrix (R) into the inner product of User (Θ) and Item (X) Matrices
Each rating of user θj on item xi is modelled as the inner product of them: rji = xiT θj
The model introduces a new quantity, k which is the rank of factorization and serves as both θ’s and Χ’s dimensions. This means that every rating in R is affected by k effects.
|
|
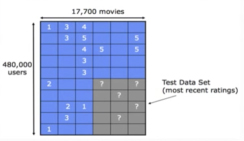
A set of training and test examples represented as a sparse matrix
So, assuming R is a matrix of users rating items, it is pretty straightforward to assume that each item is tied to one or more categories with some strength, each user likes/dislikes some item-categories with different strengths, and the rating that a user should have given an item depended on the similarity between their characteristics and this item’s characteristics.
Learning Algorithm
Model Training:
Convert matrix factorization to an optimisation problem & minimise cost function
Optimization Objective:
In each step, we are solving a regularized least square problem:
- Fixii the user feature vector, and solve for the item feature vector
- Following that, fix item feature vector mj, and solve for user feature vector.
- Simultaneously minimize the cost function J and update the values of user & item feature vector using Gradient Descent
Repeat this process until convergenceiii
The first term in the following cost function J, is the Mean Square Error (MSE); and the second term is the regularization term added to prevent overfitting.
The following function says: ‘For all the observed ratings(Rji!=NA) compute the difference between the original rating matrix R and its approximation(R - ΘT * X), then update the latent feature vectors of users and items.

Simultaneous Minimization of Cost Function J and Gradient Update, by Andrew NG iv
To monitor convergence, we plot J and number of iterations and make sure its decreasing. The learning rate α decides how fast the gradient will step forward. To choose an optimal value for a, we can
- try a number of different value ranges,
- plot J with the number of iterations
- choose the one that decreases J.
If gradient descent decreases quickly, α is efficient.
Some final notes
Apart from trying to produce a minimal value of this cost function for a given k(effects) and λ(regularization), it is essential to determine what are the optimal values for those parameters.
Large values for λ results in high bias, namely data do not fit the model while small values for λ results in high variance, namely themodel fails to generalize as new data come. We can compute different values for λ and after plotting cost function, pick the one that decreases the cost function.
Another idea is to incorporate Cross Validation or another more sophisticated optimization process to ensure a good value selection for those parameters.
Gradient descent works well in optimizing MF models only when the dimensionality of the original rating matrix is not high; as otherwise there would be many (nk + mk) parameters to optimize.
Bear in mind that introducing distributed computing could alleviate this problem.
An alternative to simultaneous optimization, is to use Alternating Least Squares which 2-teration process. In ALS, we solve a linear regression problem with the difference we do not have fixed weights. To put it differently, we solve for x given θ, compute gradient x (step 1), then we solve for θ given x, compute gradient θ (step 2) and we iterate. ALS to converge slower.
Another thing to keep in mind is that, imposed constrains shape the factorization and yield different views on data. Constrains are all the possible values variables may take.
Concluding, there are many FM techniques in which PCA and SVD are considered as baseline. Non negative MF and Probabilistic MF are also well-known MF tachniques.
i PageRank is part of Google’s overall search “algorithm” called Hummingbird.
ii Fix: Initiallize parameters with small random values
iii An iterative algorithm is said to converge when as the iterations proceed the output gets closer and closer to a specific value.
iv Discrepancy Alert: Andrew transposes θ whereas the figure on matrix factorization transposes X.
Thank You for Reading & Stay Motivated